大语言模型正在与企业应用迅速结合,并深刻改变企业的各个产业环节。而大模型训练所使用的数据包含了如文档、图片、音视频等各种类型的非结构化数据,传统关系型数据库能力有限。通过将这些非结构化数据转换为多维向量,可以结构化地在向量数据库中进行管理,实现高效的数据存储和检索过程,结合相似性检索特性,可以有效地解决大模型在知识时效性低、输入能力有限、准确度低等问题。
星环科技Transwarp Hippo作为一款企业级云原生分布式向量数据库,自发布以来受到了众多用户的欢迎,帮助用户实现向量数据的存储、管理和检索,加速大模型场景的探索和实践。为了进一步降低用户使用向量数据库的门槛和成本,Hippo推出Community Edition社区版,单机即可安装部署,开箱即用,并支持多种接口、向量/标量数据实时更新,以及多种向量检索,帮助用户低成本、快速地进行大模型场景的探索,如构建知识库、智能问答机器人等。
极简资源,极速安装
Hippo社区版仅需单台服务器即可安装部署,百万级向量数据量推荐配置仅需4核8G。all-in-one全内置设计,做到开箱即用,整个安装过程最快仅需3分钟,即可上手体验。

Hippo安装流程
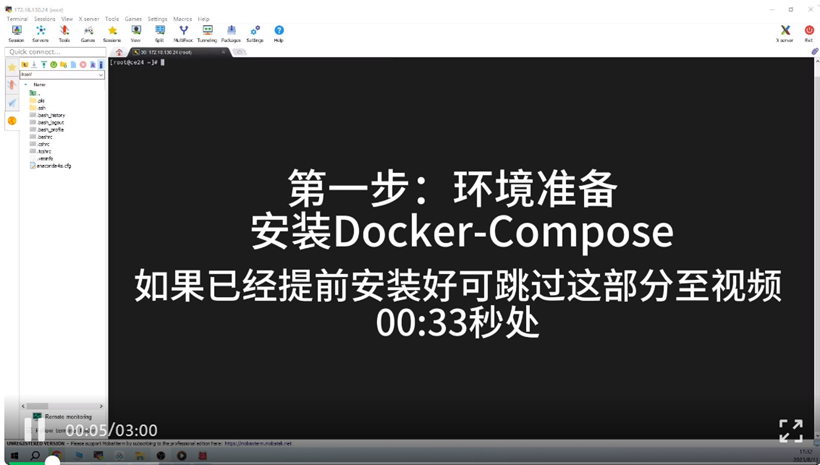
Hippo社区版安装教程
多种接口、多种检索,简单易用
Hippo社区版提供标准的Python、Restful、Java API等接口,可轻松对接各类应用和模型,提高应用开发和调用的效率。同时,提供类SQL接口,满足入库等特定场景,大幅降低使用和操作的难度。
Hippo社区版支持树索引和位图索引,支持向量topk搜索、向量/标量混合搜索和向量相似度过滤,可满足多种不同的检索场景。
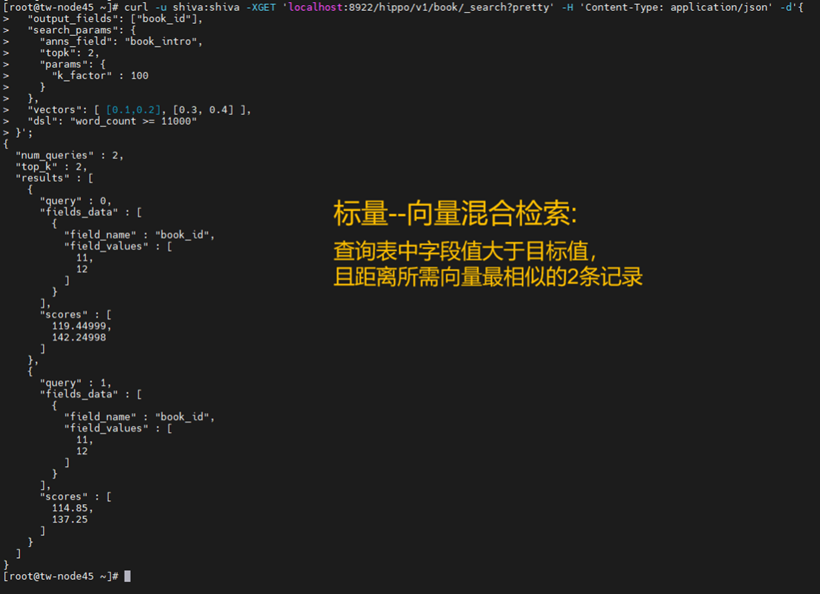
简单3步,快速搭建私有知识库
基于Hippo社区版,用户可快速搭建私有知识库。
第一步:安装向量数据库Hippo社区版、embedding model,并验证;
第二步:知识入库,将语料文档通过embedding model转化为向量,存储到Hippo中;
第三步:调用大模型,并测试连通性。
基于以上3步,即可开始智能问答。
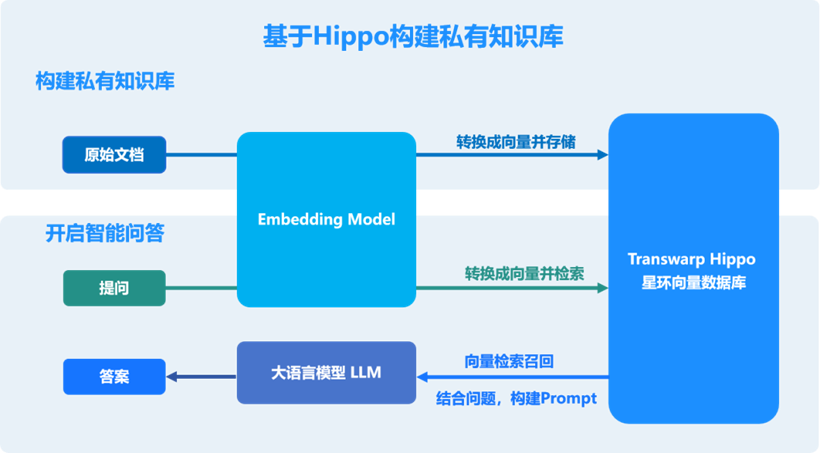
当用户发起提问时,运转流程如下:
* 向量转化并检索,通过embedding model将用户问题转化为向量,并作为Hippo的查询条件进行查询;
* 构建prompt,将检索信息与用户问题进行拼接构造prompt,作为大模型的输入;
* 大模型回答,大模型使用基础能力并结合检索信息完成对用户问题的回答。
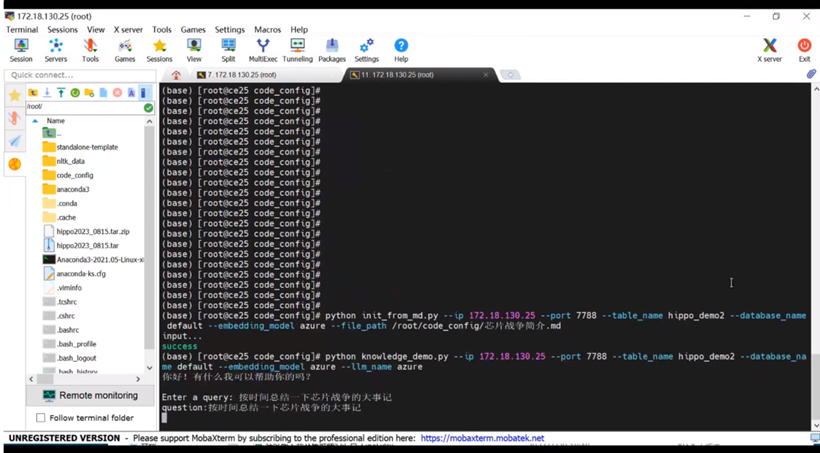
基于Hippo构建知识库的演示Demo
了解更多信息,请访问星环科技向量数据库Transwarp Hippo官网或星环开发者社区。





