★深度学习、机器学习、生成式AI、人工智能、大数据、高性能计算、ASIC、大模型训练、盘古大模型、CPU、GPU、L40S服务器、华为、英伟达、A100、H100、A800、H800、稳态微聚束、SSMB、清华 SSMB-EUV 光源、非线性动力学、AI芯片、ChatGPT、Transformer、自监督训练、高算力芯片、高粘性 CUDA、Graphcore、Habana、Cerebras、SambaNov、寒武纪、FPGA、Grace CPU、Hopper GPU、GH200、 SIGGRAPH 、HBM3e、MI300A、MI300X、Infinity Fabric、TPU、AWS、Inferentia、Trainium、Alexa、meta、MTIA
随着人工智能、大数据、高性能计算、生成式AI和大语言模型的快速发展,芯片技术和服务器市场变得越来越重要。大模型需要高性能芯片支持,而芯片技术的发展又为大模型应用和推广提供可能。在这篇文章中,我们将探讨推进芯片快速发展的技术(稳态微聚束加速器光源)、华为和英伟达显卡的对比以及赋能生成式AI和LLM大模型负载L40S服务器。
在大模型下的芯片技术领域,GPU、CPU和ASIC等技术得到了广泛应用。GPU作为图形处理器,最初是为了处理图像和游戏等任务而设计的。然而,随着人工智能和深度学习的发展,GPU逐渐成为大模型训练和推理的首选芯片。
华为和英伟达显卡在大模型服务市场中具有重要地位。华为依托其强大的技术实力和品牌影响力,在显卡市场中占据一席之地。英伟达则凭借其领先的GPU技术和广泛的应用领域,成为了大模型服务市场的领导者。在销售量和市场份额方面,英伟达略胜一筹,但是华为和其它竞争对手也在不断追赶。
GPU L40S采用先进的芯片技术,可以快速、准确地处理大规模的数据。具有高度的可扩展性,根据需要增加或减少计算资源。此外,还采用先进的算法和模型优化技术,大大提高模型训练的效率和精度。
稳态微聚束加速器光源
在芯片制造领域,光刻技术一直扮演着至关重要的角色。然而,传统的光刻技术也存在一些明显的局限性,这些局限性在新一代芯片制造中变得尤为明显。传统的光刻技术需要使用大型、昂贵的设备,如荷兰ASML公司生产的光刻机。这些设备的高成本使得芯片制造过程变得昂贵,不利于成本的降低。而且,传统的光刻技术在追求更小的制程和更高的性能时遇到了困境,因为它们受到了光源功率上限的限制。这导致了制程的瓶颈,制约了芯片技术的发展。
清华大学的唐教授提出的“稳态微聚束加速器光源”为芯片制造带来了一种全新的思路。这一方法的核心在于通过高能加速器对电子进行加速,然后让这些电子穿过交替变化的磁场,从而产生高频率和短波长的电磁波,包括可见光和X射线。简单来说就是将电子加速到接近光速,从而获得更短波长的光,为芯片制造提供了全新的工具。
一、加速器光源简介
同步辐射是带电粒子在高速运动时产生的电磁辐射,其特点包括高亮度、宽谱带、高准直性和偏振性等。自20世纪70年代起,人们开始专门建设电子储存环来产生同步辐射。一个同步辐射光源由电子注入器、电子储存环和光束线站组成,追求高亮度和更好相干性,经历四代的发展。中国大陆的北京同步辐射装置属于第一代,合肥光源属于第二代,上海光源属于第三代,正在建设的高能同步辐射光源属于第四代。同步辐射的亮度定义为单位时间、单位面积、单位发散角、0.1%带宽内的光子数。
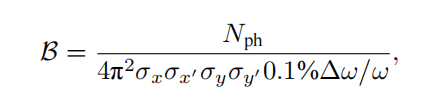
同步辐射光源的相干性包括横向和纵向两方面。横向相干性与光源尺寸有关,纵向相干性与光源谱宽有关。为获得更高亮度和相干性,需要提高辐射强度、缩小谱宽、减小电子束的发散角。同步辐射光源的发展已经降低电子束的横向发散角,从而获得良好的横向相干性,但纵向相干性仍然较弱,导致束长远超过相干长度,辐射功率较低。
自由电子激光克服这一缺点,利用电子束在波荡器中自放大发射的原理,通过电子束和辐射波在波荡器中相互作用形成微聚束,产生强相干辐射。这种正反馈过程导致辐射指数增长,与同步辐射相比,自由电子激光的峰值亮度提高8-10数量级,相干性更好,脉冲长度更短。其使用自由电子而不是束缚电子,辐射波长可以灵活调节。
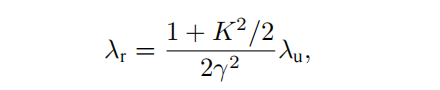
自由电子激光的辐射波长由电子束能量、波荡器参数和相对论因子γ决定,而在X射线波段,自由电子激光是唯一的相干光源。可分为低增益模式和高增益模式,早期主要是低增益模式,辐射在共振腔内被多次放大,而当前主要发展的是高增益短波长自由电子激光,即电子束单次通过波荡器就完成从发射到饱和的过程,特别是X射线自由电子激光。
高增益短波长自由电子激光对电子束质量的要求很高,需要电子束横向发散度足够小、能量散度足够小、电流足够大,以保证增益大于损耗。
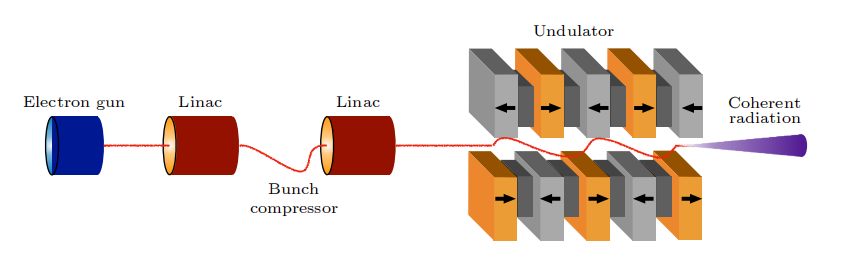
自由电子激光装置示意图
高增益自由电子激光对电子束质量要求非常高,需要高峰值电流、低发散度和低能量散度。为满足这些要求,主要依靠直线加速器产生电子束。与储存环不同,自由电子激光的重复频率较低,为获取高重复频率,正在研发采用超导射频直线加速器的自由电子激光。
加速器光源已成为人类探索物质世界的最前沿工具之一,基于电子储存环的同步辐射光源提供高重复频率的辐射,基于直线加速器的自由电子激光提供高峰值亮度的辐射,是两种主要类型的加速器光源。这两类大科学装置孕育众多突破性基础研究成果,在先进制造与产业发展中的作用难以估量。
全球有超过50个同步辐射光源和7个X射线自由电子激光装置建成或在建,最先进的加速器光源因其光束质量、科研支撑作用、建设投入和技术复杂程度,已成为国家综合实力和竞争力的重要体现。
二、稳态微聚束加速器光源原理
随着加速器光源的发展,用户需求也在不断增长,除同步辐射和自由电子激光,人们也期待出现一种同时实现高峰值功率和高重复频率的光源。2010年,Ratner和Chao首次提出一种新型储存环光源——稳态微聚束(SSMB)。
SSMB使用激光而不是射频腔来调制储存环中的电子束。由于激光与电子束的传播方向垂直,因此不能有效地交换能量。为纵向聚焦调制电子束,扭摆磁铁被采用,实现激光调制,类似于射频腔调制。
与传统储存环相比,SSMB储存环的标志是使用激光调制器代替射频腔。
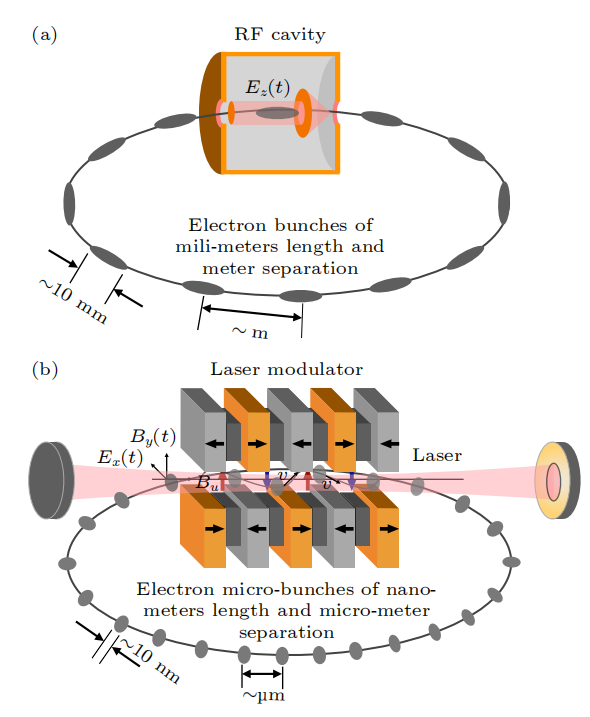
SSMB 储存环 (b) 与传统储存环 (a) 对比
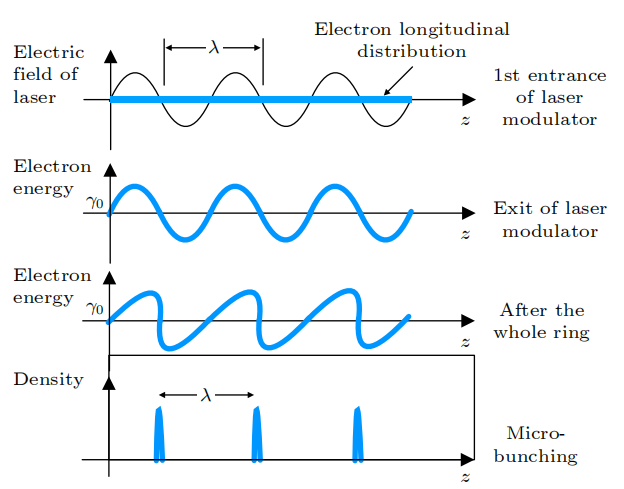
微聚束的原理示意图
在SSMB储存环中,由于激光波长比微波波长短了约6个数量级,通过精心设计的磁系统,电子束团长度可以达到亚微米至纳米量级,形成微聚束。同时,束团间隔从微波波长缩短到激光波长,使得单位长度内的束团数目提高了6个数量级。与传统束团相比,微聚束的特点是束团内电子纵向分布长度比辐射波长短,不同电子的辐射场保持相干并相干叠加,使得辐射强度与束长内电子数平方成正比,远高于非相干辐射的线性关系。
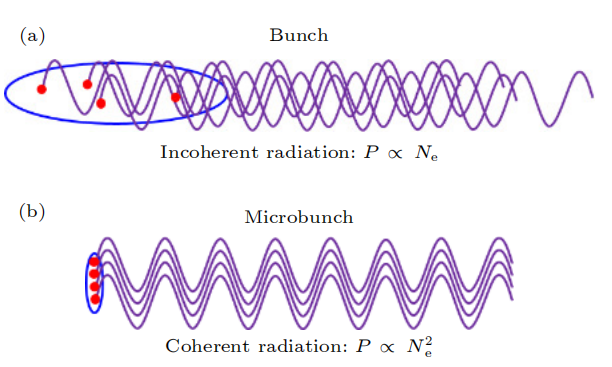
(a) 普通束团非相干辐射及 (b) 微聚束相干辐射 示意图
微聚束产生强相干辐射的原因是含有N个电子的束团辐射功率包括与N线性相关的非相干辐射和与N的平方相关的相干辐射。相干辐射显著高于非相干辐射需要束长小于辐射波长,因此纳米级束长的微聚束可产生短波长相干辐射。
高增益自由电子激光中的微聚束源自束内不稳定性,难以长期维持,而SSMB中的微聚束来自激光主动调制,是稳定的相干辐射,可在环中重复利用。SSMB结合微聚束的强相干性和储存环的高重复频率,可提供高平均功率、窄带宽的相干辐射,具有巨大的潜力。SSMB辐射的多项特性可为加速器光子科学研究和应用带来新机遇,如EUV光刻的光源等。
三、SSMB 原理的实验验证
稳态微聚束(SSMB)从概念到应用必须进行原理验证实验。清华大学等自2017年开始进行SSMB原理验证研究,利用德国的MLS准等时储存环完成了SSMB的原理验证。
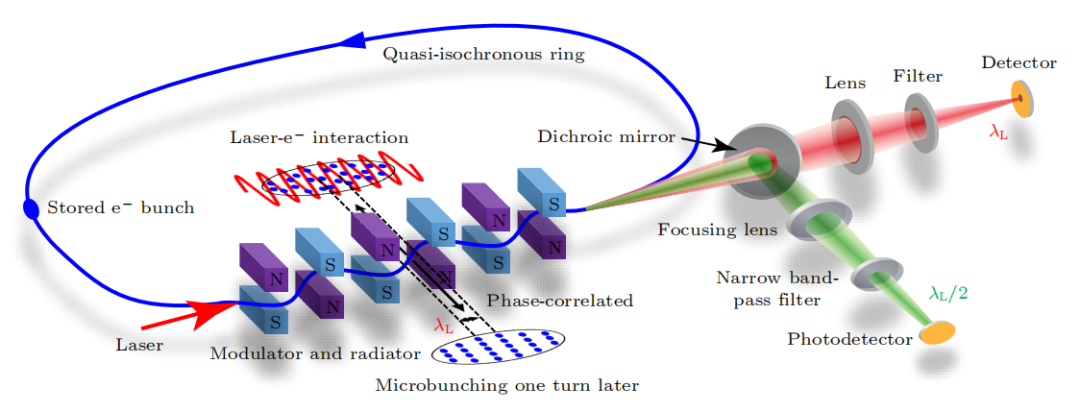
SSMB 原理验证实验示意图
在SSMB原理验证实验中,利用德国的MLS准等时储存环,电子束被激光调制能量后,形成微米量级的调制周期密度调制,即微聚束。微聚束在波荡器中发出强相干辐射,通过检测该辐射验证微聚束形成。
实验结果显示,被激光调制的电子束辐射信号得到放大,同时窄带滤波后的信号比宽谱辐射更大,证明了微聚束的窄带相干辐射。此外,还研究了辐射强度与束流强度的关系。通过这一原理验证实验,首次展示了激光调制可在环中产生微聚束并发出相干辐射的效应,完成SSMB核心概念的实验验证。
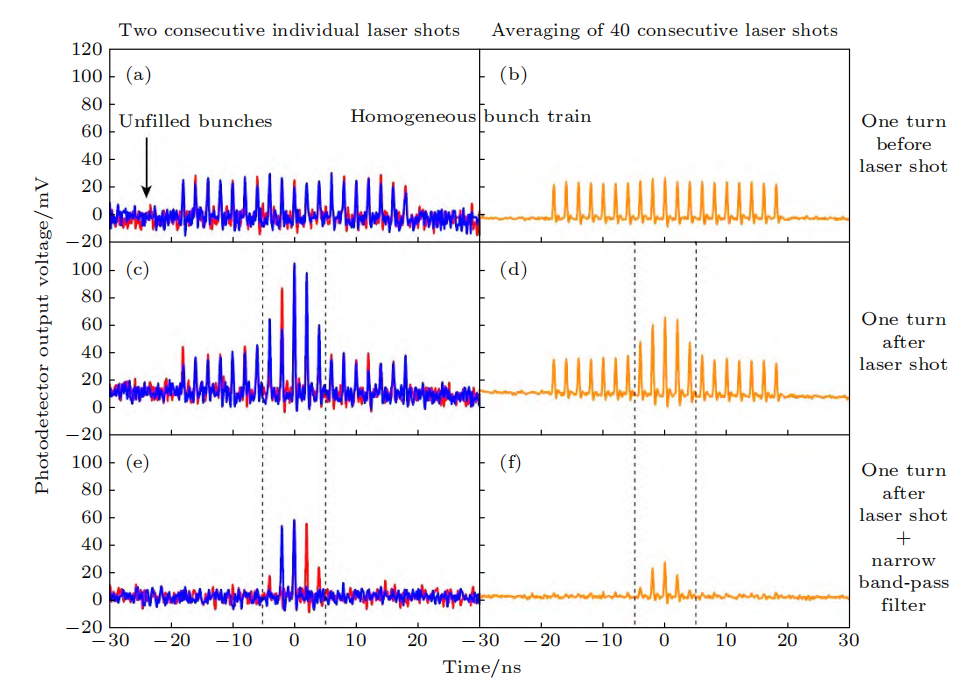
SSMB 原理验证实验结果
在实验中,还测量了辐射功率与电荷量的依赖关系,结果显示了与电荷量平方成正比的特点,这正是相干辐射最重要的特征。此外,辐射呈现窄带特性。这两点有力地证明了微聚束的形成。最近,我们还进一步实现了微聚束在储存环中多圈稳定存在,电子束实现了多圈相干发射。通过检测辐射功率关系和频谱特性,验证了微聚束形成并相干发射。进而展示微聚束可在环中多圈稳定,完成SSMB核心概念的多圈相干发射验证。
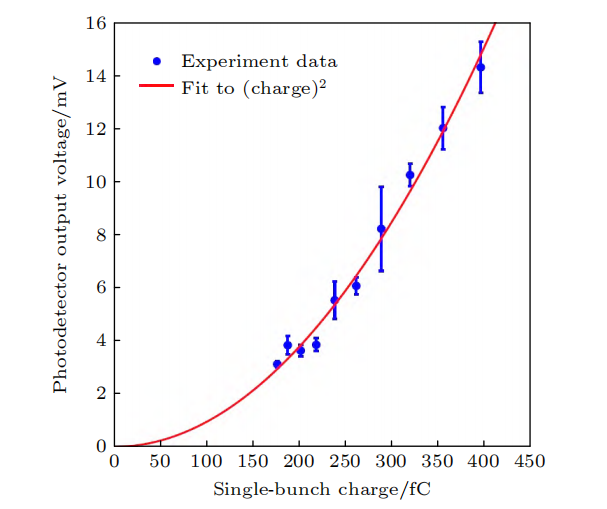
SSMB 原理验证实验结果
实验成功实现微聚束的形成和多圈稳定存在,这证明了电子纵向位置能以精确于激光波长的精度在环中关联,使电子稳定受困于激光形成的势场。这一实验与直线段上的微聚束实验不同,重点在于展示了:
1)微聚束是经过一整圈形成的,验证粒子动力学的one-turn map概念;
2)微聚束基于预先储存的电子束形成,电子束参数由储存环决定。
该实验仅展示one-turn map的一次迭代形成微聚束,而SSMB需要多次迭代实现稳态微聚束。这是从0到1的验证,标志着SSMB发展的第一个里程碑。即使在非优化环中,SSMB机理也展现出强大的鲁棒性,这激励我们构建专用环进一步完美实现SSMB。
四、SSMB 储存环的核心物理问题及关键技术挑战
SSMB原理验证实验的成功证明SSMB光源的可行性。为进一步推进SSMB光源的实际建设,需要深入研究其核心物理并解决关键技术挑战。相比传统储存环,SSMB中的束长缩短6个数量级,为加速器物理和技术的发展带来了新的机遇。下一步需要关注SSMB在环中的产生机理、SSMB的辐射特性以及技术实现方面的关键挑战。
1、SSMB 在储存环中的产生
1)SSMB是一个多次通过的装置,与电子束团单次通过的高增益FEL不同
要求超短束团在辐射段能够一圈接一圈地重复出现,即超短束团在辐射段中呈现的是该储存在环中的本征态。为了实现在较低调制激光功率下的束团压缩,对于储环的lattice设计而言,探索横纵向耦合在每一圈中的利用方式是一个新颖且有趣的课题。
2)非线性动力学效应在SSMB储存环中起着重要作用
由于对束团的操控要求精微,非线性滑相因子、非线性横纵向耦合等都可能影响束团动力学,如六维动力学孔径以及束流在六维相空间的分布。在传统储存环中,主要关注横向动力学孔径的优化,而SSMB则需要同时关注横向和纵向,即六维相空间的优化。
因此,需要发展相关的理论并结合先进的数值方法(如机器学习、遗传算法)进行SSMB的非线性动力学优化。此外,集体效应也是SSMB储存环中需要关注的问题。由于SSMB储存环中束团极短,束流的峰值流强和平均流强相对较高,相干同步辐射、束内散射以及阻抗壁尾场等都可能会对微束团结构的稳态参数以及稳定存储产生影响从而限制束流能量和强度。此外,SSMB储存环内的束流分布模式不同于传统储存环,微束团的辐射可以追上其前方的一个或多个微束团,使得通常被认为是短程的相干同步辐射在SSMB的语境下变为长程。这些因素要求对相干同步辐射、横纵向耦合导致的束团长度变化、三维任意耦合以及纵向强聚焦lattice中的IBS等进行仔细的评估和研究。
3)误差容忍度和噪声分析在非线性效应显著的SSMB中也变得非常重要
噪声对电子束团的影响按频率可分为两部分:高频噪声导致束团在相空间的扩散从而引起发射度的增长,而低频噪声会导致束团的质心运动。对于高频噪声,需要保证其对束流稳态发射度的贡献处于可接受的范围内以实现超短电子束团的形成;对于低频噪声,需要保证其对束流的影响满足绝热条件,从而使电子束团在质心受噪声影响发生移动时保证发射度不变。如果噪声对电子束的影响超出了可接受范围,需要采用相应的反馈系统或其他阻尼机制来降低噪声的影响。需要注意的是,由于SSMB的工作模式(如纵向强聚焦、强纵横耦合)不同于一般储存环,其噪声和误差容忍度的解析分析也将相对复杂。如传统射频腔相噪分析中采用的正则微扰论在纵向强聚焦储存环中就无法直接应用因为该动力系统是不可积的(混沌的)。另一方面借助于现有计算机的强大计算能力可以对噪声的影响进行直接的数值模拟研究。
2、SSMB 的辐射特性
在形成稳态微聚束后,需要研究SSMB的辐射特性。SSMB的微聚束纵向发散极小,辐射在纵向上高度相干,其束流分布模式独特。为指导设计与优化,需要研究束流在六维相空间的分布对SSMB辐射参数的影响。研究实验者已经进行相关的理论推导和程序开发。计算结果显示,在适当的参数下,SSMB可以直接实现平均功率1kW以上的EUV输出,这为SSMB的光源设计提供了指导。
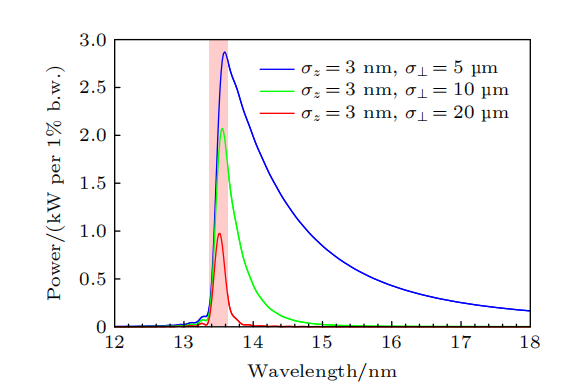
SSMB-EUV 光源辐射能谱样例
3、SSMB关键技术挑战
要实现SSMB光源的真正技术可行性,需要掌握几项核心技术。
1)激光调制器是SSMB与传统储存环之间最重要的区别
为实现SSMB,需要高激光功率、相位锁定,并采用连续波或高占空比的调制激光以提高束流占空比和辐射光的平均功率。因此,SSMB的激光调制系统采用了光学增益腔。
2)长脉冲注入系统是实现高辐射功率所必需
由于SSMB的平均流强较高,约为1A,因此需要专门设计大电荷量、长脉冲(百纳秒量级)注入束流。为了减少SSMB出光过程中的功率变化,希望其工作在流强基本恒定不变的top-up模式,同时也可降低对单次注入束流强度的要求。
3)直线感应加速器是实现SSMB束流能量补充的可行选择之一
为了提高SSMB储存环的束流占空比,需要采用连续激光,并对长脉冲电子束的能量补充提出不同于传统储存环的要求。此外,高精度磁铁、高精度控制系统等也需要在现有的同步辐射光源的基础上进一步发展。
五、清华 SSMB-EUV 光源
自2017年以来,清华团队开始研究面向EUV光刻的大功率SSMB-EUV光源。在原理验证、束流动力学、物理设计和关键技术方面取得了重要进展。在束流动力学研究中,团队解决了实现超短束所需关注的核心物理问题,完成了能够稳定储存纳米级束的储存环设计,并开展了集体效应等方面的研究。辐射理论和数值计算表明,SSMB可以实现千瓦级的EUV输出。在关键技术方面,团队搭建了光学腔平台,研制出样机,并合作研发了MHz感应加速单元等。
基于这些研究成果,团队提出了SSMB-EUV光源方案。该方案采用微波电子枪和直线加速器产生束流,经展束环调整分布后注入主环,在主环中激光调制形成稳态微聚束。微聚束在辐射段被进一步压缩,实现13.5nm EUV强相干发射,输出功率达到千瓦量级。这一创新为EUV光源技术的发展提供了新的途径。
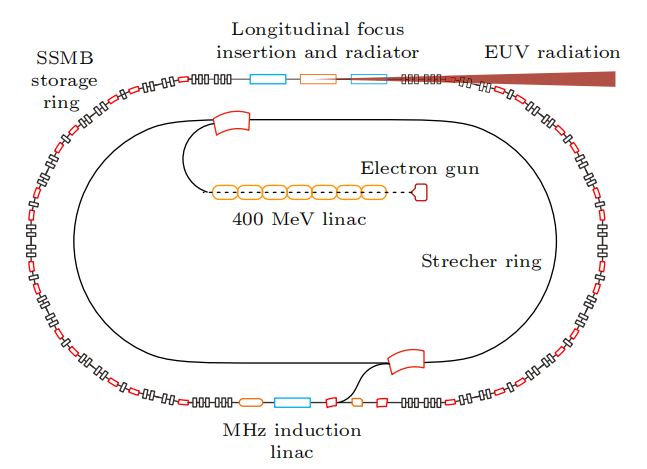
清华 SSMB-EUV 光源示意图
下面简要介绍各分系统的功能和实现方式:
1)直线注入器
直线注入器产生的能量约400MeV,它能在约10厘米间隔内提供数百个等电荷量的微脉冲束团,微脉冲束团的脉冲长度在百纳秒量级,总电荷量也是百纳库量级,平均流强为1A。
2)展束环
多脉冲束团被注入到展束环中,通过优化微脉冲束团的能散和展束环的滑相因子,使微束团长度在展束环中被拉长,相邻的束团流强分布首尾相连相互重叠,形成近似均匀流强的长度百纳秒量级的准直流电子束,然后注入到SSMB储存环中。
3)SSMB主环
被注入的束流被调制激光的势阱俘获(光学 micro-bucket),经过辐射阻尼及量子激发到达平衡,形成间隔为激光波长(约 )的微束团。SSMB主环的设计极小化了全局及局部滑相因子,从而控制全环纵向函数,使电子束实现极低的稳态纵向发射度和束团长度(十纳米到数十纳米)。储存环的非线性动力学经过仔细优化,能实现足够大的六维动力学孔径,以保证束团能稳定且具有足够寿命地储存在光学 micro-bucket 中。
4)束团压缩及辐射单元
对SSMB主环中的束团进行进一步压缩,在辐射段实现长度约为3nm的微束团,从而产生波长为13.5nm的强相干EUV光。具体的压缩方案包括纵向强聚焦、横纵向耦合(广义纵向强聚焦)等。辐射元件采用优化设计的波荡器,能产生大功率窄带宽的EUV光。
5)调制激光系统
采用窄线宽种子激光和高精细度光学增益腔,实现约1MW的平均存储功率,满足SSMB-EUV光源需求。
6)能量补充系统
采用MHz重频的直线感应加速器,补偿平均流强约为1A的束流平均功率数千瓦到十千瓦的辐射损失。
六、SSMB-EUV 光源对科学研究及芯片光刻潜在的变革性影响
目前全球唯一的 EUV 光刻机供应商是荷兰的 ASML 公司,其采用激光等离子体(LPP)的 EUV 光源。具体来说,ASML 通过一台功率大于 20 kW 的 CO 气体激光器轰击液态锡形成等离子体,从而产生 13.5 nm 的 EUV 光。
通过不断优化驱动激光功率、EUV 光转化效率、收集效率以及控制系统,LPP-EUV 光源目前能够在中间焦点处实现 350 W 左右的 EUV 光功率,该功率水平刚达到工业量产的门槛指标。产业界认为 LPP 光源未来可以达到的 EUV 功率最高为 500 W 左右,如果想要继续将 EUV 光刻向 3 nm 以下工艺节点推进,LPP-EUV 光源的功率将遇到瓶颈。
由于基于等离子体辐射的 EUV 光源功率进一步突破困难,因此基于相对论电子束的各类加速器光源逐渐进入产业界的视野,如基于超导直线加速器技术的高重频 FEL 以及 SSMB 等。
SSMB-EUV 光源用于 EUV 光刻具有以下特点和潜在优势:
1、高平均功率
SSMB储存环支持安装多条EUV光束线,可同时作为光刻大功率照明光源及掩模、光学器件的检测光源,还可以为EUV光刻胶的研究提供支撑
2、窄带宽与高准直性
SSMB光源容易实现EUV光刻所需的小于2%的窄带宽要求,并且波荡器辐射集中于mrad的角度范围内。窄带宽以及高准直的特性可为基于SSMB的EUV光刻光学系统带来创新性的设计,同时可以降低EUV光学反射镜的工艺难度
3、高稳定性的连续波输出
SSMB输出的是连续波或准连续波辐射,可以避免辐射功率大幅涨落而引起的对芯片的损伤。储存环光源的稳定性好,采用top-up运行模式的SSMB储存环可使光源的长时间可用性得到进一步提升
4、辐射清洁
与LPP-EUV光源相比,波荡器辐射的高真空环境对光刻的光学系统反射镜不会产生污染,镜子的使用寿命可以大大延长
5、可拓展性
SSMB原理上容易往更短波长拓展,为下一代采用波长6.x nm的Blue-X光刻技术留有可能
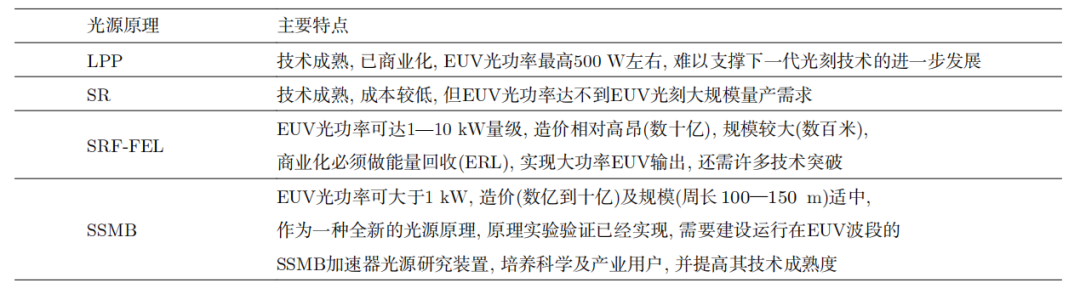
各类 EUV 光源特点
SSMB-EUV光源的成功研制将有望推动我国EUV光刻技术的跨越式进步。与此同时,SSMB加速器光源能够产生高平均功率、窄线宽的从太赫兹到软X射线的相干辐射,并且其时间结构可调范围广泛,这将对物理、化学、能源、环境等学科的基础研究与应用研究带来全新的研究工具和手段。
计算机视觉的目标是设计能识别和处理视觉信号的程序,使计算机"看"得更好。典型任务有图像分类、物体检测、分割、追踪和姿态估计。ImageNet数据集包含超过2万个物体类别,用于图像分类。MS-COCO数据集包含检测、分割等任务。
在计算机中,视觉信号以像素密集采样的方式来存储光强度。然而,像素并不代表语义信息,因此这种存储形式与人类理解之间存在巨大的差距
华为盘古大模型介绍
AI正在逐渐深入到企业的核心生产系统中,并发挥出更大的价值。预计到2025年,企业采用AI的比例将达到86%,而当前这一数字仅为4%。在众多的AI项目中,有600+已经得到实践,其中30%已经进入了生产系统。然而,AI在各行各业的应用仍然面临诸多挑战,如场景碎片化、作坊式开发方式导致规模化复制困难、行业知识与AI技术结合难度大、以及人们对AI模型安全性、隐私和潜在攻击的担忧。

近年来,云计算市场迅速发展,客户需求从资源需求向智能和业务方案需求转变。市场前景广阔,但业务数量众多、场景复杂也带来挑战。随着市场的成熟,定制化解决方案相较于统一方案更具优势,中小型供应商也具有了竞争力。然而,在保证业务规模的同时,如何控制成本、提高效率和质量成为核心难题。
另一方面,传统行业也在积极利用AI技术解决问题,这需要算法具备通用性。然而,目前AI开发主要采取的是针对每个场景独立开发的模式,缺乏通用知识的积累。这也导致低水平开发者难以掌握规范流程和优化技巧,进而影响模型的效果。
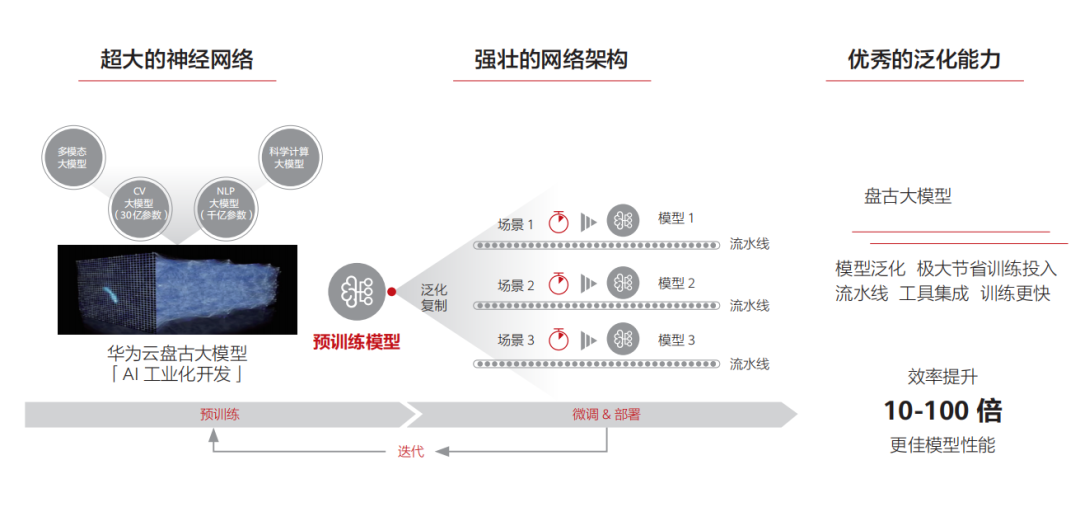
为解决AI算法落地面临的碎片化问题,预训练大模型应运而生。这种模型通过无监督学习从大规模数据中提取通用知识,并将其储存在参数量巨大的模型中。在遇到具体任务时,只需要调用统一的流程来应用这些知识,并结合领域经验来解决具体问题。近年来,预训练模型的研究和应用持续爆发,有望在AI领域发挥统领作用。然而,要实现预训练模型的商业规模应用,还有一段路要走,这需要技术和商业模式双轮驱动。我们设想大模型可以成为AI的操作系统,管理硬件资源,支撑算法应用,从而使AI开发更加规范和普及。
一、大模型 是 AI 发展的必然趋势
1、人工智能发展趋势的总体研判
人工智能存在着逻辑演绎、归纳统计和类脑计算三大流派,各具优势并持续争议。类脑计算目标远大,但缺乏生命科学支撑。归纳演绎方式与人类相似,可解释性强,是前两次繁荣的主角。随着对人工智能困难性的理解,逻辑方法的局限性被放大,统计学习在第三次繁荣期占据主导地位。深度学习进一步推崇“抛弃先验,拥抱数据”的思想。

深度学习是当代产物,得益于大数据和大算力的支持,其核心是深度神经网络,通过通用骨干网络与特定目的头部网络的配合,实现了对各个子领域的统一解决问题。然而,其本质仍是统计学习的框架,缺乏人类基于知识的推断方式,导致通用性受限,且开发成本高昂,难以惠及细分行业。
预训练大模型是深度学习时代的集大成者,分为上游(模型预训练)和下游(模型微调)两个阶段,旨在解决上述问题。虽然预训练大模型不直接导向人工智能,但两个重要判断对其未来发展有着深远影响。
1)在下一个划时代的计算模型出现以前,大模型将是人工智能领域最有效的通用范式, 并将产生巨大的商业价值
根据实际操作经验,预训练大模型加持下的人工智能算法(包括计算机视觉和自然语言处理等领域)相比于普通开发者从头搭建的算法,精度显著提高、数据和计算成本明显降低,并且开发难度大大降低。以计算机视觉为例:在以前,要在100张图像上训练基础物体检测算法,需要8块GPU运行5个小时,一名开发者需要工作1个星期才能完成。然而,有了预训练模型的支持,现在只需要1块GPU运行2个小时,而且几乎不需要人力干预。综合人力和算力开销的考虑,上述案例的开发成本降低90%甚至99%。
2)对大模型的研究,将有可能启发下一个通用计算模型
在2011年之前,统计学习方法盛行,词袋模型的参数达到了10亿量级。然而,2012年只有6000万参数的深度网络打败了词袋模型,推动了计算机视觉领域的发展。深度网络相比词袋模型,在特征提取效率上取得了突破性进展。我们预测,随着大模型不断发展,结合知识后可能会出现新的突破,推动统计学习的进化。
目前看来,预训练大模型代表了统计学习的最高成就,也是当前人工智能的最强武器。在新技术出现之前,预训练大模型将继续引领人工智能研发。中美两国已经在大模型的研发和应用方面展开了竞争。

二、盘古大模型家族介绍
华为云团队在2020年启动大模型研发项目,并于2021年4月首次公开了名为“盘古预训练大模型”的成果。盘古大模型集合了华为在AI领域的多项研究成果,并深度结合昇腾芯片、MindSpore语言和ModelArts平台。下面将简要介绍盘古大模型的组成部分,并剖析构建大模型的关键技术。
1、视觉大模型
计算机视觉的目标是设计能够识别和处理视觉信号的程序,从而使计算机能够更好地“看”。其典型任务包括图像分类、物体检测、分割、追踪和姿态估计。ImageNet数据集包含超过2万个物体类别,用于图像分类任务,而MS-COCO数据集则包含检测和分割等任务。

在计算机中,视觉信号以像素密集采样的方式来存储光强度。然而,像素并不代表语义信息,因此这种存储形式与人类理解之间存在巨大的差距,这被称为语义鸿沟,是计算机视觉的核心问题。进一步分析图像信号的特点,发现以下几点:
内容较复杂
图像的基本组成单元是像素,但单个像素通常不足以传达语义。
信息密度低
图像信号虽然能客观地反映出事物的特征,但其中相当一部分数据用于表达图像中的低频区域(如天空)或无明确语义的高频区域(如随机噪声)。
域丰富多变
图像信号受到各种域的影响,这种影响通常具有全局性质,难以与语义区分开来。例如,同样的语义内容在不同的光照条件下会呈现出完全不同的表征。同时,相同的物体以不同的尺寸、视角和姿态出现时,会在像素层面产生巨大差异,给视觉识别算法带来困难。

基于此使用了卷积网络和Transformer等主流视觉模型架构。自动机器学习算法支持不同规模模型,最大规模近30亿参数,最小仅数十万,可适配不同任务。
训练数据主要来自互联网,不含准确语义标签。采用自监督学习方法,通过设计代理任务让模型在无标签数据上拟合分布。在对比学习基础上改进了自监督算法,引入等级化语义相似度挑选更优质的正样本,并使用混合数据增强技术减少噪声影响。还扩大了正样本数目,避免负样本对训练的影响。
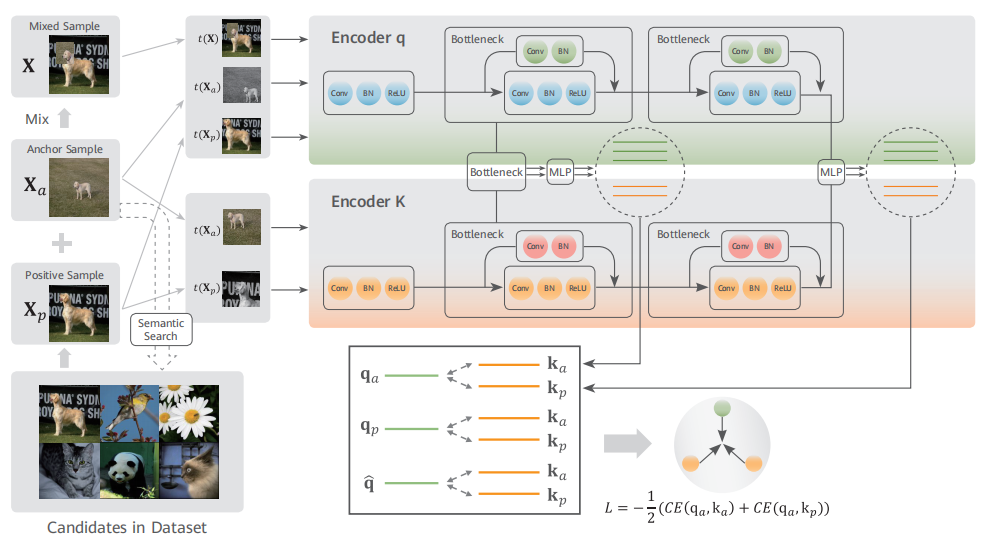
基于等级化语义聚集的对比度自监督学习
2、语音语义大模型
自然语言是人类存储和交换信息的重要方式,通过文字和语音两种形式实现。因此,语音语义处理分为自然语言处理和语音处理两个领域,目标都是让机器像人类一样理解和使用语言。自然语言处理和语音处理都包含理解和生成两个方面,但处理的信号类型不同,一个是文本,一个是音频。虽然文本和音频大多数情况下高度相关,但也有一些独特的表达情况。
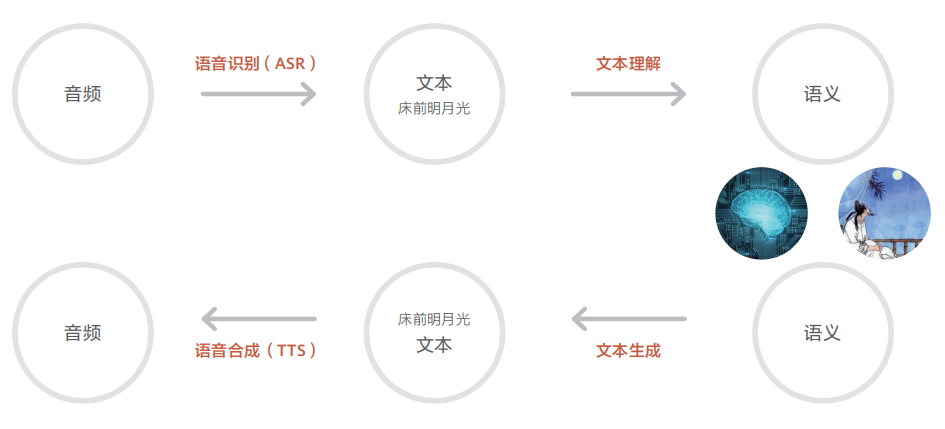
语音语义处理的核心是将文字和声音转化为机器可处理的格式。在深度学习之前,主要通过特征工程实现,但这种方法依赖于专家知识且难以扩展。随着深度学习的发展,自动学习语言的向量表示逐渐成为主流。编码器-解码器框架被用于处理文字和音频信号,其中编码器将语言映射到低维向量,解码器将低维向量映射回语言。设计合适的网络结构和学会参数是深度学习中的关键技术问题。在小型模型时代,CNN和RNN技术占主导地位,而LSTM模型因处理远距离依赖的能力而备受关注。然而,RNN的优化不稳定且难以并行计算,因此限制了构建大型语言模型的规模。
2017年,自注意力Transformer模块被提出,结合已有方法优点,在速度和表达能力上具有巨大优势,迅速在自然语言处理和语音识别领域得到应用。随着大规模语料库的出现和自监督学习方法的成熟,2018年出现了预训练模型BERT并进入大模型时代。现在,预训练大模型凭借出色的泛化能力和基于提示的微调技术,简化各种下游任务的实现方式,推动自然语言处理和语音识别领域的巨大发展,成为语音语义处理领域的最佳方案。
1)数据收集
自然语言处理和语音识别类似于计算机视觉,也需要大规模数据集作为基础。爬取40TB原始网页数据,通过解析和清洗,使用正则表达式等方法过滤噪声、去重和规范长度,最终得到约647GB文本数据。语音部分,爬取超过7万小时普通话音频数据,转换为音频文件,共计约11TB,视频来源多样。

2)预训练方法
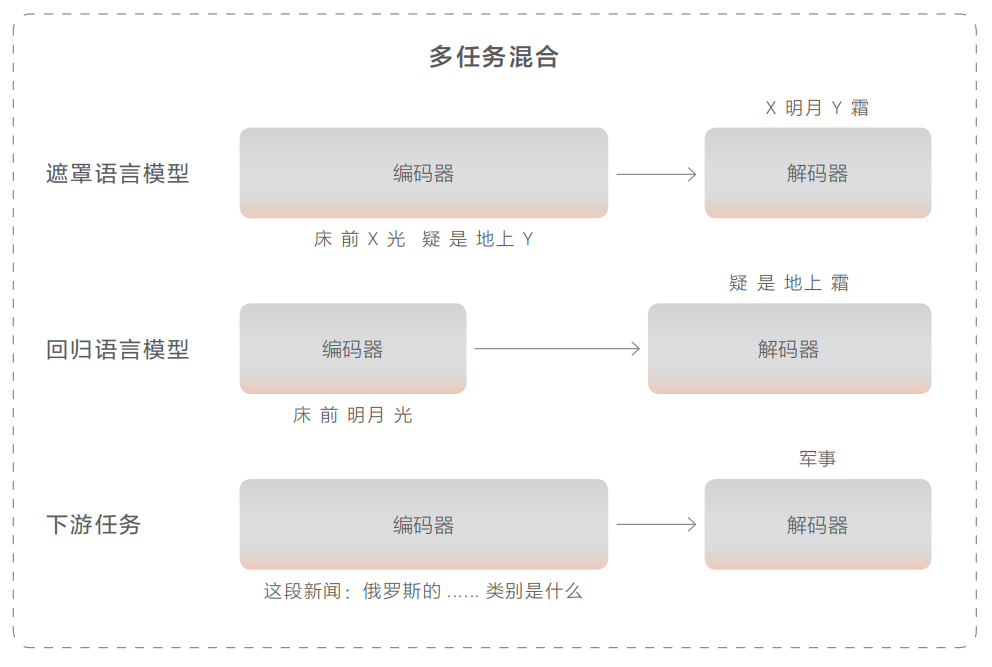
对于语义部分,使用基于Transformer的编码-解码器神经网络模型。编码器采用双向自注意力机制来理解文本,解码器则通过单向自注意力逐词生成文本。提出多任务融合策略来让模型从海量文本数据中获取语言知识。遮罩语言模型用于训练理解能力,即对原文进行挖空并预测缺失的部分。回归语言模型用于训练生成能力,给定上文,预测下文。为提高零样本推理能力,收集了100+下游任务数据并加入预训练中。
对于语音部分,解码器与文本解码器相似,但音频编码器采用了卷积与Transformer结合的网络结构。底层卷积神经网络提取局部信息,上层Transfomer提取全局信息。使用对比学习策略,将音频中的片段挖空并与随机负例进行比较,以找出正确的被挖掉的片段。
3、多模态大模型
多模态任务不同于计算机视觉或自然语言处理等单一模态任务,需要在海量多模态数据上进行预训练,并将预训练知识迁移到下游各项任务中,以提升下游任务的精度。典型的多模态任务包括跨模态检索(如以文搜图或以图搜文)、视觉问答(通过图像内部信息回答问题)和视觉定位(在图像中定位描述的对应区域)。

1)数据收集
与视觉和语音语义大模型一样,多模态大模型的训练也需要在大量高质量数据上进行。采用了业界常用的做法,从互联网上爬取大量图文数据,通过过滤算法消除不符合要求的数据,最终得到高质量的图文配对数据,用于多模态大模型的预训练。具体来说,设定了大量文本关键字,在搜索引擎上获取与之匹配的图像,并将图像对应的文本存储下来,形成图文配对数据池。在去掉重复数据后,进一步筛选出分辨率高、文本长度适中的数据。接着,使用已有的多模态预训练模型对配对数据的相似度进行判断,如果相似度太低,就丢弃文本描述并使用图像自动描述算法来生成文本数据。经过上述预处理过程,最终得到了约3.5亿高质量的图文配对数据,占据约60TB存储空间。

2)预训练方法
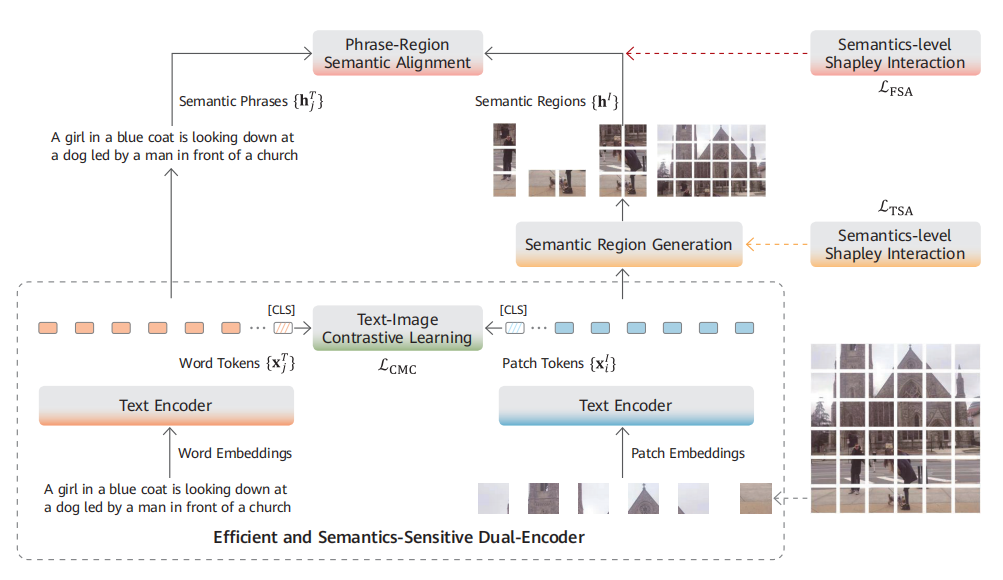
多模态大模型预训练的关键在于不同模态数据的高效交互和融合。当前主流的多模态大模型架构分为单塔架构和双塔架构。单塔架构使用一个深度神经网络(一般是 Transformer)实现图像和文本之间的交互融合,属于信息前融合方案;而双塔架构使用不同的神经网络来完成不同模态的信息抽取,并在最后一层进行信息交互和融合,属于信息后融合方案。
盘古大模型采用双塔架构,具有模型独立性强、训练效率高等优势。实现方式简单,使用相应网络抽取图像和文本特征,然后将一个批次的图像和文本特征送入判别器,在对比损失函数的作用下,使得配对的跨模态特征聚集在一起,而不配对跨模态特征被拉远。在大数据集上充分迭代后,模型就能学会将图像和文本对齐到同一空间。此时,图像和文本的编码器可以独立用于各自下游任务,或协同用于跨模态理解类下游任务。
、
4、科学计算大模型
视觉大模型、自然语言大模型和多模态大模型主要用于解决通用的人工智能问题,如音频分析、图像识别和语义理解等。人类能够标注大规模数据集供深度神经网络学习这些问题。然而,在自然科学领域中,还存在许多人类无法解决的问题,比如湍流模拟、天气预报和大形变应力建模等。这些问题具有广泛的应用前景,如下所示:
近年来,随着人工智能技术的迅速发展,业界出现了AI+科学计算方法,即使用嵌入科学方程的深度神经网络,直接从观测和仿真数据中学习问题蕴含的规律,以分析复杂的科学数据并了解科学过程的内部机理。
从预训练大模型的角度看,科学计算大模型与其他大模型有许多相似之处。都依赖于大规模数据集、需要设计具有大量参数的神经网络、经历复杂的优化过程,并将知识存储在网络参数中。接下来,将简单描述科学计算的独特之处。
1)数据收集
在AI+科学计算场景中,数据分为观测和仿真两类。观测数据由工具产生,如游标卡尺等,仿真数据由算法产生。这些数据、融合数据和机理知识都可以作为AI模型的学习对象。不同场景的观测数据差异大,需使用专业仪器与实验系统收集,如蛋白质结构预测中的X射线衍射和核磁共振等。仿真数据来自算法输出,蕴含丰富的数学物理信息。同一个问题使用不同算法可产生不同仿真数据,精度受限。相对于观测数据,仿真数据通常更大,可有效扩充数据。在某些场景中,观测和仿真数据结合机理知识生成融合数据,如气象再分析数据。

2)模型构建
根据输入数据的性质,算法会选择合适的基础模型进行海浪预测等科学计算任务。对于二维球面数据,适合使用二维网络模型;而三维数据则需使用三维网络模型。这两种模型可借鉴计算机视觉领域的卷积神经网络和视觉 Transformer 模型进行预训练。同时,科学计算的特点在于利用人类经验形成约束性质的偏微分方程组,将其嵌入神经网络中可增强模型的鲁棒性并降低拟合难度和不稳定。
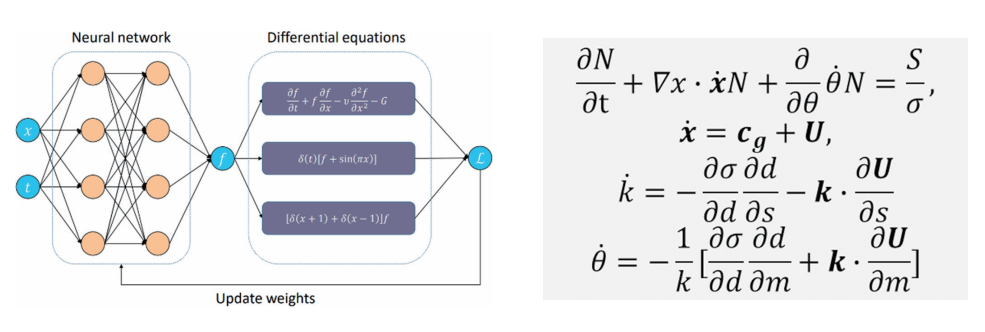
左图为嵌入偏微分方程的神经网络示意图,右图为海浪预报问题使用的偏微分方程
3)案例和效果展示
下面我们来探讨一个典型的科学计算案例,即全球海浪高度预测系统。海浪预测的输入和输出都是经纬度网格点上的气象要素数据,数据形式与视频数据相似。但海浪数据是浮点数,不同于视频数据的像素值。此外,海浪数据还满足球坐标条件下的一系列不变性,因此需要选定满足特定不变性的CNN或者Transformer架构。
盘古海浪预测模型的主体是考虑了旋转不变性的视觉Transformer架构,参数量约为五亿。模型的损失函数由两部分组成:实际数据上的预测误差和海浪预测本身需要满足的偏微分方程。通过使用全球近10年的实时海浪高度数据进行训练,模型在验证集上预测的平均误差小于5cm,与传统预测方法相当,完全可以满足实际应用需求。更重要的是,AI算法的预测时间较传统方法大幅减少:在单张华为昇腾芯片上,1s之内即可得到全球海浪高度预测,1分钟内能够完成超过100次海浪预测任务,推理效率较传统方法提升了4-5个数量级。
使用AI算法可以迅速得到不同可能的风速条件下的海浪高度,进行实时预测和未来情况模拟,对渔业养殖、灾害防控等场景具有极大的价值。
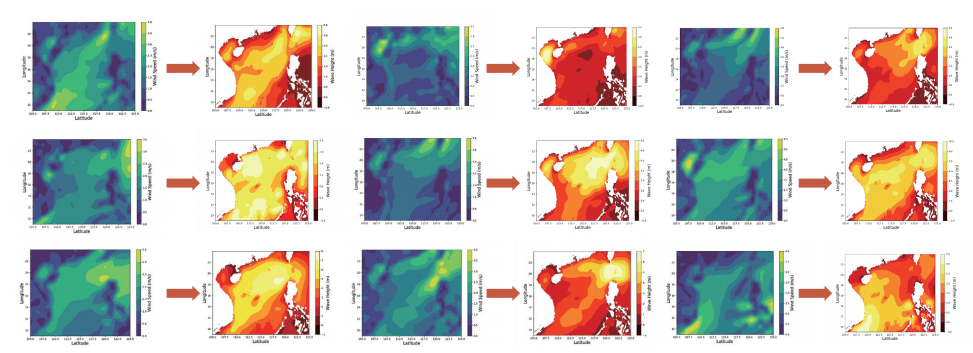
使用昇腾 AI 芯片,AI 模型可以在一秒内给出成百上千组“随机”风速分布下的海浪分布
AI芯片:群贤毕至,花落谁家?
最近,由ChatGPT引领的AI热潮再次兴起,国内外科技公司纷纷投入到大语言模型和生成式AI的研发中,展开一场对计算能力的竞赛。GPT背后的核心算法是谷歌在2017年提出的Transformer,这种算法通过采用自我监督预训练的方式,近乎无需人工干预,因此需要大量训练数据,再加上少量的有监督微调和强化学习相结合。随着更为复杂和多元化模型的涌现,高算力的AI芯片将充分受益于这种发展趋势。然而,如果这些技术在消费端的应用仅仅停留在表面,那么其意义并不大。
一、英伟达的两大护城河:高算力芯片和高粘性 CUDA 软件生态
根据AI论文中不同芯片的引用数据,英伟达的芯片在AI研究领域广受欢迎。其产品的使用率是ASIC的131倍,高出Graphcore、Habana、Cerebras、SambaNova和寒武纪五家公司总和的90倍,是谷歌TPU的78倍,是FPGA的23倍。通常,在人工智能领域,新模型的推出都会在相关论文中进行发表,以便于信息交流与学术合作。英伟达在人工智能相关论文中的引用数量遥遥领先,这反映新算法需要采用英伟达GPU的必要性,以及其在学术界长期以来的重要地位和影响力。
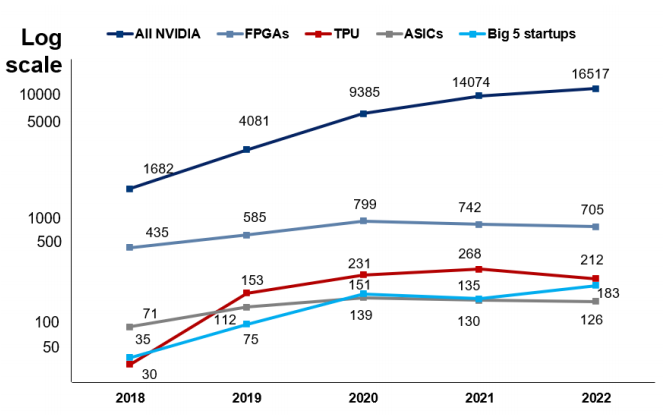
英伟达芯片在 AI 论文中的引用数量遥遥领先
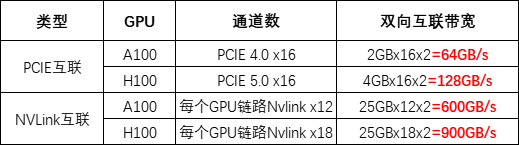
英伟达一直致力于开发高性能计算芯片的迭代,不断在产品工艺、计算能力和存储带宽等方面进行创新。针对高性能计算和深度学习应用场景,英伟达基于其芯片架构,推出一系列GPU产品,以提升张量核心和稀疏矩阵计算等功能。2023年,英伟达不满足于单GPU的更新换代,推出结合Grace CPU与Hopper GPU的GH200超级芯片,实现高达900GB/s的总带宽,加速大规模AI和HPC应用计算。在SIGGRAPH上,英伟达的AI芯片再次迎来升级,推出全球首次采用HBM3e内存的GH200超级芯片。该芯片的带宽高达每秒5TB,并提供141GB的内存容量,适用于复杂的生成式人工智能工作负载,如大型语言模型、推荐系统和矢量数据库等。

英伟达 H100 与部分同业产品在运行不同 AI 负载时表现
二、MI300A 和 GH200:CPU+GPU AI 芯片架构仿生人脑结构
MI300系列是AMD旗下的GPU产品,包括两款产品:MI300X和MI300A。MI300X是一款纯GPU产品,由12个chiplets(8个GPU+4个IO+Cache)组成,与英伟达的GPU H100相媲美。而MI300A是一款CPU+GPU产品,由13个chiplets(6个GPU+3个CPU+4个IO+Cache)组成,采用APU架构(Zen 4 CPU + CNDA 3 GPU),与英伟达的异构CPU+GPU芯片GH200竞争。
在参数上,MI300系列有许多值得关注的亮点。MI300X的192GB HBM3内存领先于英伟达H100双卡NVL的188GB HBM3,更远超过H100 PCIe和SMX的80GB HBM3,而MI300A的128GB HBM3内存也具有竞争力。其次,MI300X的晶体管数量为1530亿,MI300A的晶体管数量为1460亿,与H100的800亿相比具有明显优势。此外,内存带宽5.2TB/s与英伟达H100的2-7.2TB/s相近,Infinity Fabric互联带宽的896GB/s与NVlink的900GB/s相差无几,但比H100高2.4X的HBM密度以及1.6X HBM带宽则展示了AMD在GPU技术方面的优势。
AMD在2023 CES大会上首次推出CPU+GPU的MI300,后改称MI300A。作为MI系列的第一款CPU+GPU异构产品,CPU+GPU架构已成为AI芯片的趋势。
在AI应用中,GPU算力较高,适用于并行计算,在视频处理、图像渲染等方面具有优势,但并不是所有工作负载都只需要单纯的GPU处理,还需要由CPU进行控制调用,发布指令。因此,在CPU+GPU架构中,CPU可以负责控制和发出指令,指示GPU处理数据和完成运算(如矩阵运算)。MI300A中的CPU采用的是x86架构,而GH200中的CPU采用的是ARM架构。两种架构各有优势,一般来说,ARM架构主要应用于移动端,因此相比x86能耗较低,这一点在AI和数据中心的应用中都会受到青睐。
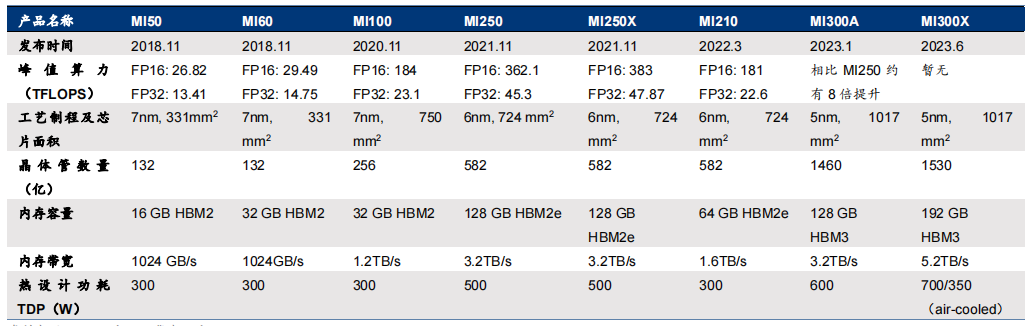
AMD Instinct MI 系列 GPU 发展历程
三、谷歌 TPU:少数能与英伟达高算力 GPU 匹敌的 AI 芯片
谷歌的TPU(Tensor Processing Unit)是云厂商自研AI芯片的典型例子之一,从2017年开始已具备训练和推理能力。谷歌TPU是少数能够与英伟达高算力GPU相匹敌的AI芯片。在架构与性能参数上不断迭代,第一代TPU从2015年开始被使用于谷歌云计算数据中心的机器学习应用中,当时仅面向推理端,但从2017年推出第二代开始,TPU已同时拥有训练和推理能力。第三代TPU于2018年发布,旨在提高性能和能效以满足不断增长的机器学习任务需求。第四代TPU于2021年发布,而专为中大规模训练和推理而构建的TPUv5e于2023年发布。与TPUv4相比,TPUv5e可为大语言模型提供高达2倍的训练性能和2.5倍的推理性能,并能节约一半以上的成本。谷歌目前仅通过谷歌云服务平台向外部客户提供TPU的算力租赁服务,而未有将其作为硬件产品出售。
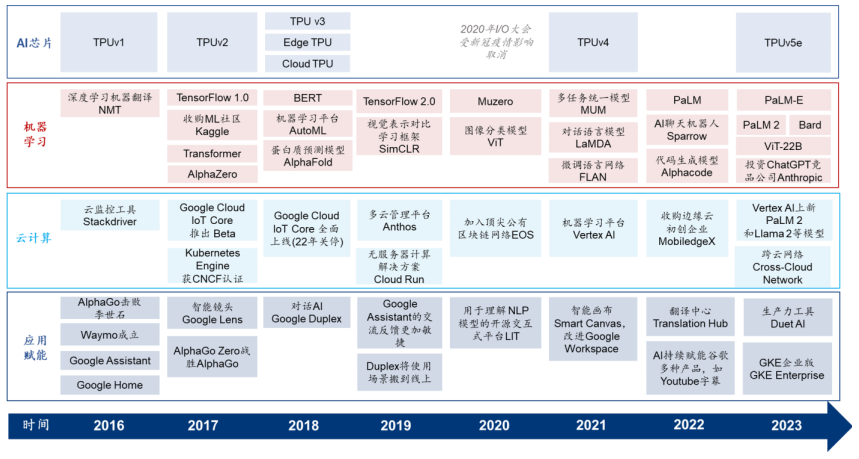
2016 年至今谷歌云计算、AI 芯片、机器学习及 AI 应用赋能进程梳理
四、亚马逊 AWS:Trainium & Inferentia,训练推理双管齐下
AWS于2018年和2020年分别发布AI推理芯片Inferentia和训练芯片Trainium,随后在2023年推出第二代Inferentia,并在AWS云上提供给客户使用。亚马逊在2015年收购以色列芯片设计公司AnnapumaLabs,从而开始自研AI芯片的旅程,而第一代Inferentia正是源自该公司的技术。AWS的AI芯片搭配AWSNeuron开发软件包,其中包含可用于兼容TensorFlow和PyTorch的编译器。2023年5月,亚马逊表示计划将其自研的大语言模型“AlexaTeacherModel”(AlexaTM)接入智能语音助手Alexa。Alexa此前已经接入亚马逊Echo智能音箱等智能硬件设备,并使用Inferentia进行推理。
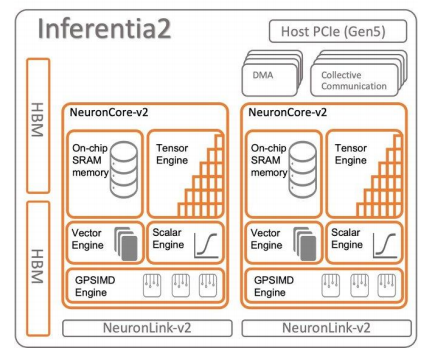
AWS Inferentia2 芯片架构
Trainium是一款在云端进行训练的AI芯片,其表现相较于A100更为优秀,同时也具有更高的性价比。Trainium是AWS专为超过1000亿参数规模的大模型打造的AI芯片,于2020年发布,目前仍处于第一代。每个Trainium配备了容量为32GB、带宽为820GB/s的HBM2e,提供了FP16算力190TFLOPS(英伟达A100的FP16算力为624TFLOPS)和FP32算力47.5TFLOPS,并支持包括可配置的FP8在内的多种数据精度。Trainium使用的互联技术是AWS的Neuronlink(超高速非阻塞互连技术,v2代),互联速度达到了768GB/s,相比之下,NVlink4.0的互联速度为900GB/s。根据AWS官网的信息,Trainium实例的内存容量比英伟达A100实例高出60%,互联带宽高出2倍。使用130个Trainium实例训练GPT-3只需要2周,而根据英伟达与微软的论文《Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM》,使用1024颗A100进行训练需要34天。2022年,AWS推出的Trn1AI平台可以部署最多16个Trainium,在AWS云上进行AI模型训练。相较于同类型的AmazonEC2实例,以Trainium为支撑的Trn1实例可以节约50%的训练成本,而在亚马逊广告模型训练中,这一成本节约甚至高达70%。
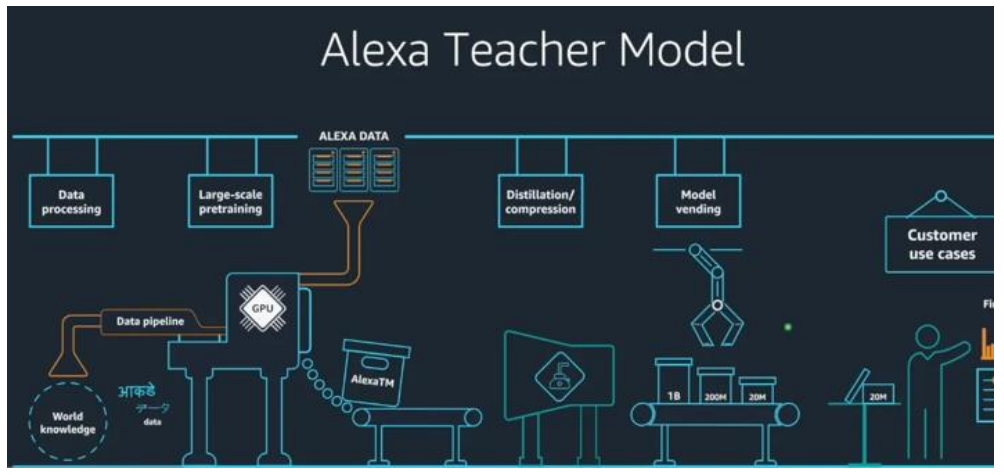
AWS 的 in-house 大语言模型 Alexa Teacher Model
Inferentia 推理卡已经迭代两代,并被用于亚马逊硬件终端的 AI 服务。2018 年推出的第一代 Inferentia 配备了 8 GB 带宽为 50GB/s 的 DDR4 内存,而 2023 年 4 月正式推出的第二代 Inferentia 2 则配备了 32 GB 带宽为 820GB/s 的 HBM2e 内存,FP16 算力达到 190 TFLOPS,相比一代 Inferentia(64 TFLOPS)提高2 倍,主要针对高性能深度学习推理应用程序进行设计。
根据亚马逊官网的信息,相比第一代 Inferentia,第二代的延迟降低十分之一,吞吐量提高四倍。由于大规模终端设备 AI 模型对云端推理能力要求较高,而自研 AI 芯片等信息基础设施和自身应用可以进行针对性的相互适配与优化,Amazon 人工智能助手 Alexa 使用以 Inferentia 为支撑的 Inf 实例进行推理负载。
除与 AWS 生态捆绑外,客户还可以通过开发工具包 AWS Neuron,以及使用 Amazon Sagemaker(AWS 机器学习平台)、Amazon Elastic Container Service(ECS,AWS 容器托管方案)、Amazon Elastic Kubernetes Service(EKS)等服务来快速开始使用 Inf 和 Trn 实例,并分别使用底层 Inferentia 和 Trainium 芯片能力。目前 AWS 上使用 Inferentia 承担推理工作负载的客户包括 Airbnb(爱彼迎,房屋租赁平台)、Snap(图片类社交媒体平台)、Sprinklr(SCRM 社交媒体营销公司)、Money Forward(金融科技公司)和 Finch Computing(AI 初创公司)等;而使用 Inferentia2 的客户则包括 Hugging Face(机器学习公司)、Qualtrics(自动化管理软件公司)和 Finch Computing(亦为 Inf1 客户)等。
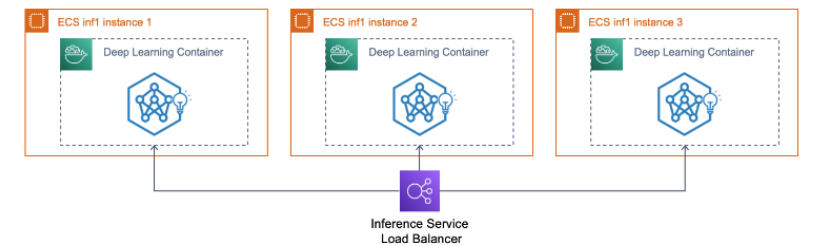
使用 inf1 实例将推理服务部署到 AWS ECS 容器托管集群
五、meta:首个自研推理端芯片 MTIA 将于 2025 年问世
meta 在 2023 年 5 月发布自主研发的 AI 芯片 MTIA,该芯片主要针对推理工作,从 2020 年开始设计,预计于 2025 年正式推出,采用台积电 7nm 制程。MTIAv1 是针对推理端的产品,使用最高 128GB 的 LPDDR5 内存,采用 RISC-V 架构,并配合基于 PyTorch 的软件包。与其他云厂商自主研发的 AI 芯片类似,MTIA 是针对公司内部应用和模型量身定制的 ASIC,尤其是针对 meta 旗下产品所需的 feed(例如 Instagram 的用户浏览界面)贴文推荐算法进行了优化。与通用芯片相比,MTIA 可以实现降本增效。

MTIA 产品实物图
meta 的超级计算机由约 16,000 片英伟达 A100 GPU 构成,已被用于训练 LLaMA 模型。目前,meta 没有推出专用于训练阶段的芯片,而是使用基于英伟达 A100 GPU 的内部生产集群进行训练。meta 的 AI 超级计算机 RSC(Research Super Cluster)由约 16,000 片英伟达 A100 GPU 构成(2000 台英伟达 DGX A100),通过 NVIDIA Quantum InfiniBand 16 Tb/s 网络结构进行连接。meta 表示,其使用 RSC(除此外还包括由 A100 GPU 组成的内部生产集群)来训练其在 2023 年 2 月发布的 70-650 亿参数的开源大模型 LLaMA。其中,650 亿参数的 LLaMA 模型在 2048 片英伟达 A100 GPU 上花费 21 天完成预训练。2023 年 7 月,meta 发布了免费可商用的 LLaMA2 版本,与第一代相比,LLaMA2 作为升级版本包括 70 亿、130 亿和 700 亿三个参数版本,使用了 1.4 倍容量的数据集,并采用了分组查询注意力机制,同样使用 RSC 工作负载进行预训练。据 meta 评估,多项测评结果显示 LLaMA 2 在推理、精通性、编码和知识测试等诸多外部基准测试中均优于其他开源语言模型。
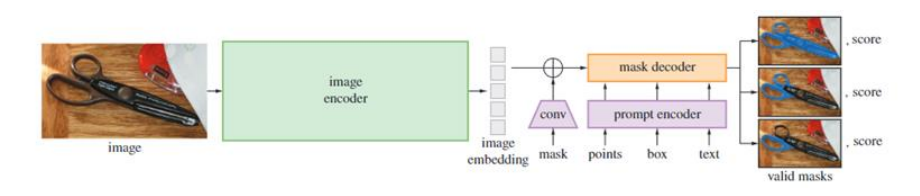
SAM 模型总览示意图
英伟达显卡与华为对比
当谈到千卡集群GPT3模型训练性能时,华为当代Atlas集群以其卓越的表现领先于NV DGXA800集群1.2倍。华为当代Atlas集群作为一种先进的计算平台,以其出色的计算能力和高效的数据处理能力而闻名,为大规模深度学习模型的训练任务提供了有力的支持。
华为当代Atlas集群的卓越性能源于其先进的硬件设计和优化的软件架构。该集群采用了高性能的GPU加速器和高速互联网络,这使得数据传输和计算速度得以显著提升。这种卓越的硬件设计与华为自主研发的优化算法和分布式训练框架相结合,进一步提升了模型训练的效率。
与NV DGXA800集群相比,华为当代Atlas集群在千卡集群GPT3模型训练性能上具有明显的优势。使用华为当代Atlas集群进行训练任务,能够以更快的速度完成模型训练,从而提高工作效率。这种领先性能的差距不仅体现在训练时间上,还可以在模型的收敛速度和训练结果的质量上得到体现。
华为当代Atlas集群的领先性能使其成为深度学习研究人员和工程师的首选。无论是进行大规模数据训练还是进行复杂模型的训练任务,华为当代Atlas集群都能够提供卓越的性能和可靠的支持,帮助用户更快地实现预期的训练目标。

蓝海大脑大模型训练平台
蓝海大脑大模型训练平台提供强大的算力支持,包括基于开放加速模组高速互联的AI加速器。配置高速内存且支持全互联拓扑,满足大模型训练中张量并行的通信需求。支持高性能I/O扩展,同时可以扩展至万卡AI集群,满足大模型流水线和数据并行的通信需求。强大的液冷系统热插拔及智能电源管理技术,当BMC收到PSU故障或错误警告(如断电、电涌,过热),自动强制系统的CPU进入ULFM(超低频模式,以实现最低功耗)。致力于通过“低碳节能”为客户提供环保绿色的高性能计算解决方案。主要应用于深度学习、学术教育、生物医药、地球勘探、气象海洋、超算中心、AI及大数据等领域。

一、为什么需要大模型?
1、模型效果更优
大模型在各场景上的效果均优于普通模型
2、创造能力更强
大模型能够进行内容生成(AIGC),助力内容规模化生产
3、灵活定制场景
通过举例子的方式,定制大模型海量的应用场景
4、标注数据更少
通过学习少量行业数据,大模型就能够应对特定业务场景的需求
二、平台特点
1、异构计算资源调度
一种基于通用服务器和专用硬件的综合解决方案,用于调度和管理多种异构计算资源,包括CPU、GPU等。通过强大的虚拟化管理功能,能够轻松部署底层计算资源,并高效运行各种模型。同时充分发挥不同异构资源的硬件加速能力,以加快模型的运行速度和生成速度。
2、稳定可靠的数据存储
支持多存储类型协议,包括块、文件和对象存储服务。将存储资源池化实现模型和生成数据的自由流通,提高数据的利用率。同时采用多副本、多级故障域和故障自恢复等数据保护机制,确保模型和数据的安全稳定运行。
3、高性能分布式网络
提供算力资源的网络和存储,并通过分布式网络机制进行转发,透传物理网络性能,显著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用严格的权限管理机制,确保模型仓库的安全性。在数据存储方面,提供私有化部署和数据磁盘加密等措施,保证数据的安全可控性。同时,在模型分发和运行过程中,提供全面的账号认证和日志审计功能,全方位保障模型和数据的安全性。
三、常用配置
1、处理器CPU:
Intel Xeon Gold 8358P 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8350C 32C/64T 2.6GHz 48MB,DDR4 3200,Turbo,HT 240W
Intel Xeon Platinum 8458P 28C/56T 2.7GHz 38.5MB,DDR4 2933,Turbo,HT 205W
Intel Xeon Platinum 8468 Processor 48C/64T 2.1GHz 105M Cache 350W
AMD EPYC™ 7742 64C/128T,2.25GHz to 3.4GHz,256MB,DDR4 3200MT/s,225W
AMD EPYC™ 9654 96C/192T,2.4GHz to 3.55GHz to 3.7GHz,384MB,DDR5 4800MT/s,360W
2、显卡GPU:
NVIDIA L40S GPU 48GB
NVIDIA NVlink-A100-SXM640GB
NVIDIA HGX A800 80GB
NVIDIA Tesla H800 80GB HBM2
NVIDIA A800-80GB-400Wx8-NvlinkSW